Transforming Visions: Redefining Possibilities with Apps
We develop cutting-edge apps that significantly impact people's lives. By transforming real-time challenges into opportunities, we drive growth and success.
 Launched 50+ app-based products
Launched 50+ app-based products
 13 awards for best digital product
13 awards for best digital product
 50 million active users
50 million active users

As featured in





Our Expertise at Daeken
 Use advanced OpenAI models like GPT-4 and DALL-E2 to build photo and video editing solutions.Leveraging AI and ML models and algorithms to build time tracking and management solutions for the enterprise.Creating a custom, secured shared planning solution for enterprises, small businesses, and families.Our core expertise is to convert a digital product idea into a successful solution.
Use advanced OpenAI models like GPT-4 and DALL-E2 to build photo and video editing solutions.Leveraging AI and ML models and algorithms to build time tracking and management solutions for the enterprise.Creating a custom, secured shared planning solution for enterprises, small businesses, and families.Our core expertise is to convert a digital product idea into a successful solution.Top Products Built by Daeken

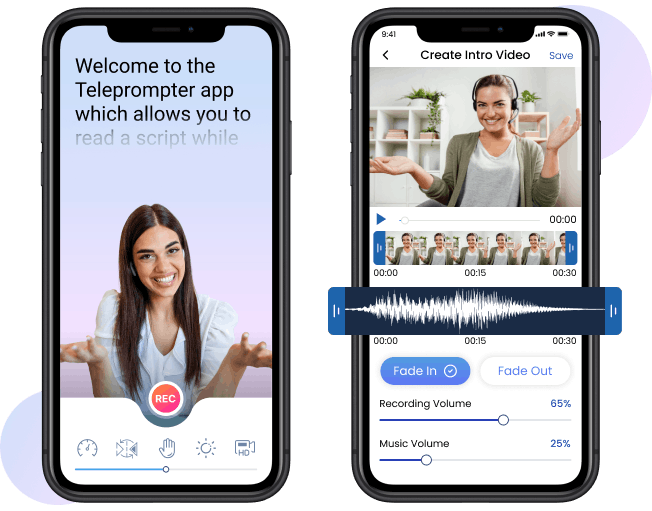
Turn your smartphone into a teleprompter studio. Enhance your YouTube videos and presentations with ease using our Teleprompter app, featuring AI-guided script scrolling for recording videos from start to finish.
Features of Teleprompter App
- AI-powered scripting guidance
- Vertical recording
- Audio monitoring
- Multi-take recording
- Green screen effect


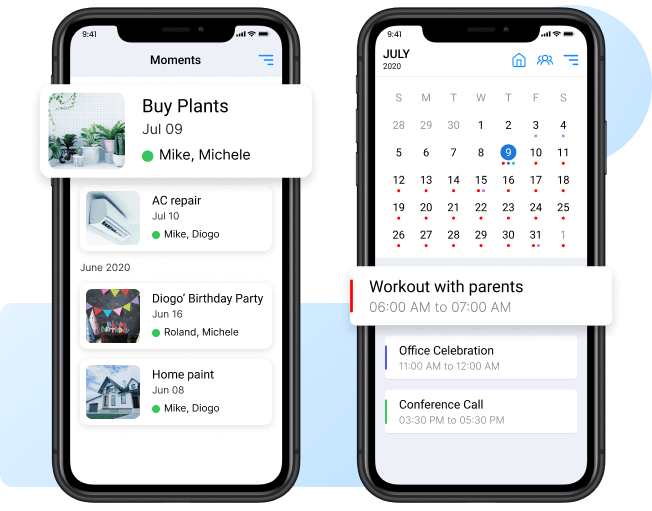
Simplify family life with Daeken, your all-in-one family organizer. Our Daeken app provides a shared calendar, grocery lists, memos, and tasks to make family communication and collaboration easy.
Features of the Daeken App
- Family member management
- Family calendar
- Grocery and to-do lists
- Family moments
- Reminder and notification

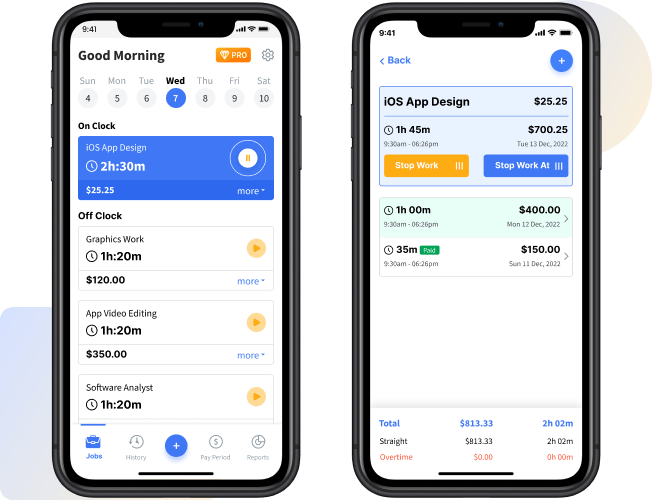
Boost productivity and manage tasks with ease using our Workday Hours Tracker app. An app that simplifies tasks, boosts efficiency, reduces stress, and enables you to efficiently manage time management every day.
Features of the Workday Hours Tracker App
- Set timers
- Break management
- Productivity graphs
- Personal notes
- Custom alarms
Engineering Pioneers: Shaping Tomorrow

FAQ About Daeken
What does Daeken specialize in?
We are a tech company that specializes in developing digital solutions to solve real-world problems. Our expertise lies in using artificial intelligence and machine learning to create innovative products.
What are Daeken's notable products?
We offer a diverse portfolio of apps, and two products have gained exceptional recognition. The Teleprompter for Video app is designed for professionals like YouTubers and broadcasters, making video production easier. The Daeken Family Organizer app helps families manage their schedules, grocery lists, and memos in a centralized platform.
What technologies does Daeken utilize?
Daeken employs cutting-edge technologies, including OpenAI models like GPT-4 and DALL-E2. These advanced AI and ML algorithms enable us to offer unique and effective solutions in photo and video editing, and time management.